类似 Neo4j 这样的图数据库在国内会兴起么?为什么?
关注者
395被浏览
168,13524 个回答

https://www.linkev.com/?a_aid=itlr
用过Community版本写过一个项目,最大的感受是对应用层非常友好,不存在往数据库引入新的实体(node)和关系(relation)很难操作的情况,从业务建模的角度来说是无敌的;改RDBMS的schma就要纠结多了。
好学好用,优势多多,不过现在还没有发展到一个引爆点,选型成熟的大项目往neo4j迁移恐怕很少人会做,应用成熟程度是无法和传统RDBMS比的,看新生项目和新生代的公司了。

在NoSQL领域,从最近十年的表现来看图数据库已经成为关注度最高,发展趋势最明显的数据库类型。从图数据库的优势和趋势上来看前景很好,特别是图数据库在处理大数据方面的优势,会让图数据库越来越像关系型数据库一样流行。
近年来图数据库的几个典型应用场景:知识图谱、金融风控、社交关系等场景也使得图数据库这个新技术与AI相结合,在人工智能领域发挥重要基础作用。相信强人工智能时代图数据库技术更是不可或缺,因为感知智能之上的认知智能,比如记忆提取、关联推理、归纳、探索、联想等都是依赖于记忆点构建起来的复杂网络之上的决策过程。
图数据库技术已经在国内兴起了,不仅有越来越多的使用者,也出现越来越多的开发者。近几年来国内也有一些公司在研发图数据库,包括百度、阿里、华为等。
下面是从图数据库中查询出的电影关系图谱:
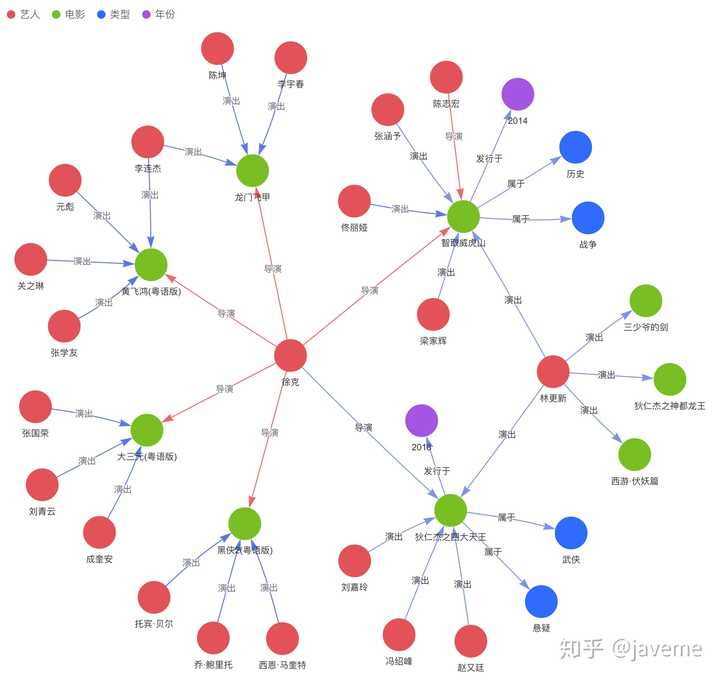

图数据库技术的兴起有其自身的原因:
- 使用图(或者网)的方式来表达现实世界的关系很直接、自然,易于建模。比如某人喜欢看某电影,就可以建立一条边连接这个人和这部电影,这条边就叫做“喜欢”边,同时这个人还可以有其它边,比如“朋友”边、“同学”边等,同样这个电影也可以有其它边,比如“导演”边、“主演”边等,这样就构建了自然的关系网。
- 图数据库可以很高效的插入大量数据。图数据库面向的应用领域数据量可能都比较大,比如知识图谱、社交关系、风控关系等,总数据量级别一般在亿或十亿以上,有的甚至达到百亿边。mysql不做分表分库的情况下插入百万数据基本就慢到不行,图数据库基本能胜任亿级以上的数据,比如neo4j、titan(janus)、hugegraph等图数据库,持续插入十亿级的数据基本还能保持在一个较高的速度。
- 图数据库可以很高效的查询关联数据。传统关系型数据库不擅长做关联查询,特别是多层关联(比如查我的好友的好友有哪些人),因为一般来说都需要做表连接,表连接是一个很昂贵的操作,涉及到大量的IO操作及内存消耗。图数据库对关联查询一般都进行针对性的优化,比如存储模型上、数据结构、查询算法等,防止局部数据的查询引发全部数据的读取。
- 图数据库提供了针对图检索的查询语言,比如Gremlin、Cypher等图数据库语言。图查询语言大大方便了关联分析业务的持续开发,传统方案在需求变更时往往要修改数据存储模型、修改复杂的查询脚本,图数据库已经把业务表达抽象好了,比如上面的2层好友查询,Gremlin实现为g.V(me).out('friend').out('friend'),如果需要改为2层同学查询,那调整一下把好友换为同学即可g.V(me).out('classmate').out('classmate')。
- 图数据库提供了专业的分析算法、工具。比如ShortestPath、PageRank、PersonalRank、Louvain等等,不少图数据库还提供了数据批量导入工具,提供了可视化的图显示界面,使得数据的分析结果更加直观展示出来。