








Kylin的数据模型
Kylin的数据模型本质上是将二维表(Hive表)转换为Cube,然后将Cube存储到HBase表中,也就是两次转换。
第一次转换,其实就是传统数据库的Cube化,Cube由CuboId组成,下图每个节点都被称为一个CuboId,CuboId表示固定列的数据数据集合
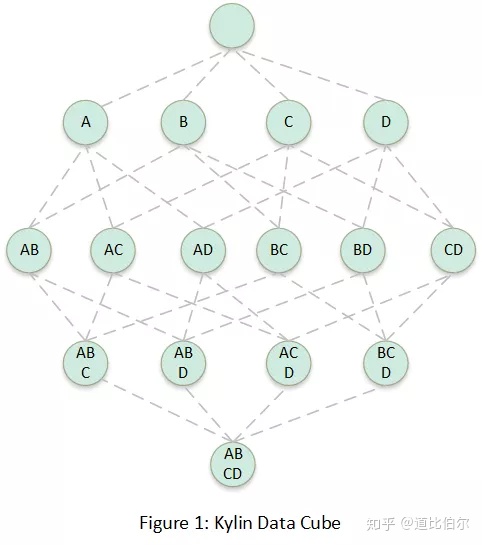
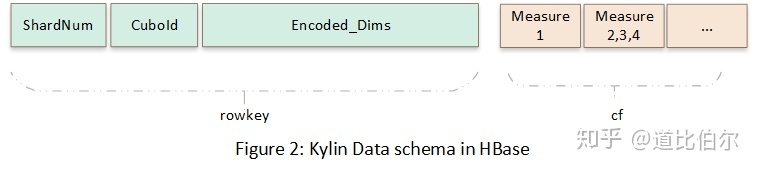
第二次转换,是将Cube中的数据存储到HBase中,转换的时候CuboId和维度信息序列化到rowkey,度量列组成列簇。在转换的时候数据进行了预聚合。下图展示了Cube数据在HBase中的存储方式。
Kylin的索引结构
因为Kylin将
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3045
3045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









