Prometheus集群介绍-1
Prometheus监控介绍
公司做教育的,要迁移上云,所以需要我这边从零开始调研加后期维护Prometheus;近期看过二本方面的prometheus书籍,一本是深入浅出一般是实战方向的;官方文档主要内容大概也都浏览了一遍;在此做个总结;会分几篇内容来写;
本篇从Prometheus的单集群监控开始,介绍包括Prometheus的基本概念,基本原理,基于联邦架构的多集群监控,基于Thanos的多集群监控;
1.Prometheus基本原理
简介
Prometheus是当前最流行的开源多维监控解决方案,集采集,存储,查询,告警于一身。主要用于K8S集群的监控,其拥有强大的PromSQL语句,可进行非常复杂的监控数据聚合计算,且支持关系型聚合。其基本架构如下图所示。
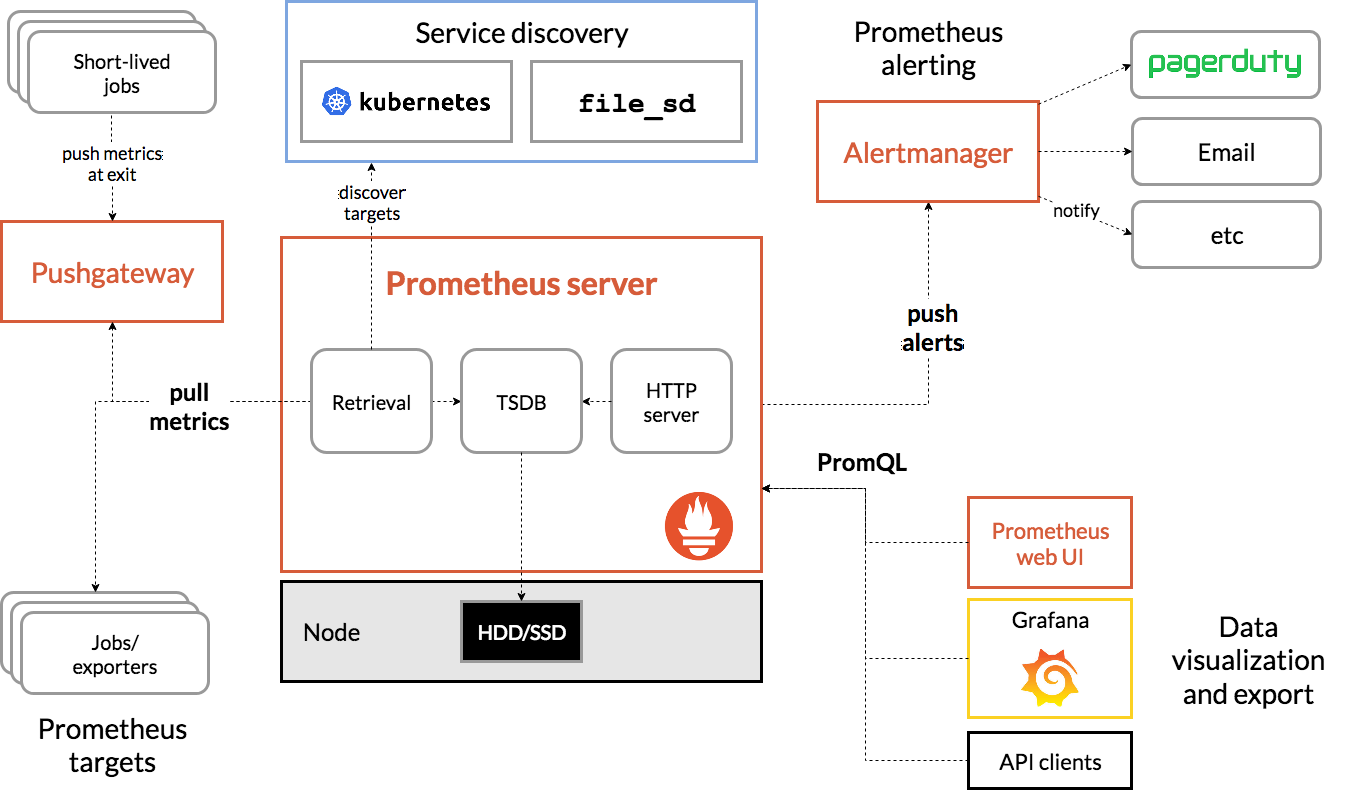
乍一看图可能比较乱,简单说明如下:
- 从配置文件加载采集配置
- 通过服务发现探测有哪些需要抓取的对象,也可以配置静态的
- 周期性得往抓取对象发起抓取请求,得到数据,也就是metrics
- 将数据写入本地盘或者写往远端存储
- push需要发送警报的内容到Alertmanager组件
- 可通过grafana或者自带的webUI展示数据
基本概念
job: Prometheus的采集任务由配置文件中一个个的Job组成,一个Job里包含该Job下的所有监控目标的公共配置,比如使用哪种服务发现去获取监控目标,比如抓取时使用的证书配置,请求参数配置等等。
target: 一个监控目标就是一个target,一个job通过服务发现会得到多个需要监控的target,其包含一些label用于描述target的一些属性。
relabel_configs: 每个job都可以配置一个或多个relabel_config,relabel_config会对target的label集合进行处理,可以根据label过滤一些target或者修改,增加,删除一些label。relabel_config过程发生在target开始进行采集之前,针对的是通过服务发现得到的label集合。
metrics_relabel_configs:每个job还可以配置一个或者多个metrics_relabel_config,其配置方式和relabel_configs一模一样,但是其用于处理的是从target采集到的数据中的label。也就是发送在采集之后;
series(序列):一个series就是指标名+label集合。
head series:Prometheus会将近2小时的series缓存在内测中,称为head series;
基本原理
服务发现:Prometheus周期性得以pull的形式对target进行指标采集,而监控目标集合是通过配置文件中所定义的服务发现机制来动态生成的。也可以静态配置;
relabel:当服务发现得到所有target后,Prometheus会根据job中的relabel_configs配置对target进行relabel操作,得到target最终的label集合。
采集:进行完上述操作后,Prometheus为这些target创建采集循环,按配置文件里配置的采集间隔进行周期性拉取,采集到的数据根据Job中的metrics_relabel_configs进行relabel,然后再加入上边得到的target最终label集合,综合后得到最终的数据。
存储:Prometheus不会将采集到的数据直接落盘,而是会将近2小时的series缓存在内测中,2小时后,Prometheus会进行一次数据压缩,将内存中的数据落盘。
流程:服务发现 ==> targets ==> relabel ==> 抓取 ==> metrics_relabel ==> 缓存 ==> 2小时落盘
2.单集群监控方案
我现在用的就是单机群监控方案,后面多机房后,会用多集群监控方案;
对于单个集群,有几个主流的指标来源方式,于以下几个组件,Prometheus将从他们获取数据。
Kube-state-metrics: 通过watch API Server生成资源对象的状态指标,比如Deployment、Pod、Service等,然后Prometheus进行采集;
metrics-server:metrics-server 一个集群范围内的资源数据聚合工具,是 Heapster 的替代品,比如kube-controller-manager状态信息;
Node-exporter: 用于监控K8s节点的基本状态,这个组件以DeamonSet的方式部署,每个节点一个,用于提供节点相关的指标,比如节点的cpu使用率,内存使用率等等;
Cadvisor: 这个组件目前已经整合到kubelet中了,它提供的是每个容器的运行时指标,比如一个容器的cpu使用率,内存使用率等等;
kube-state-metrics 主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等
metrics-server 主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标。
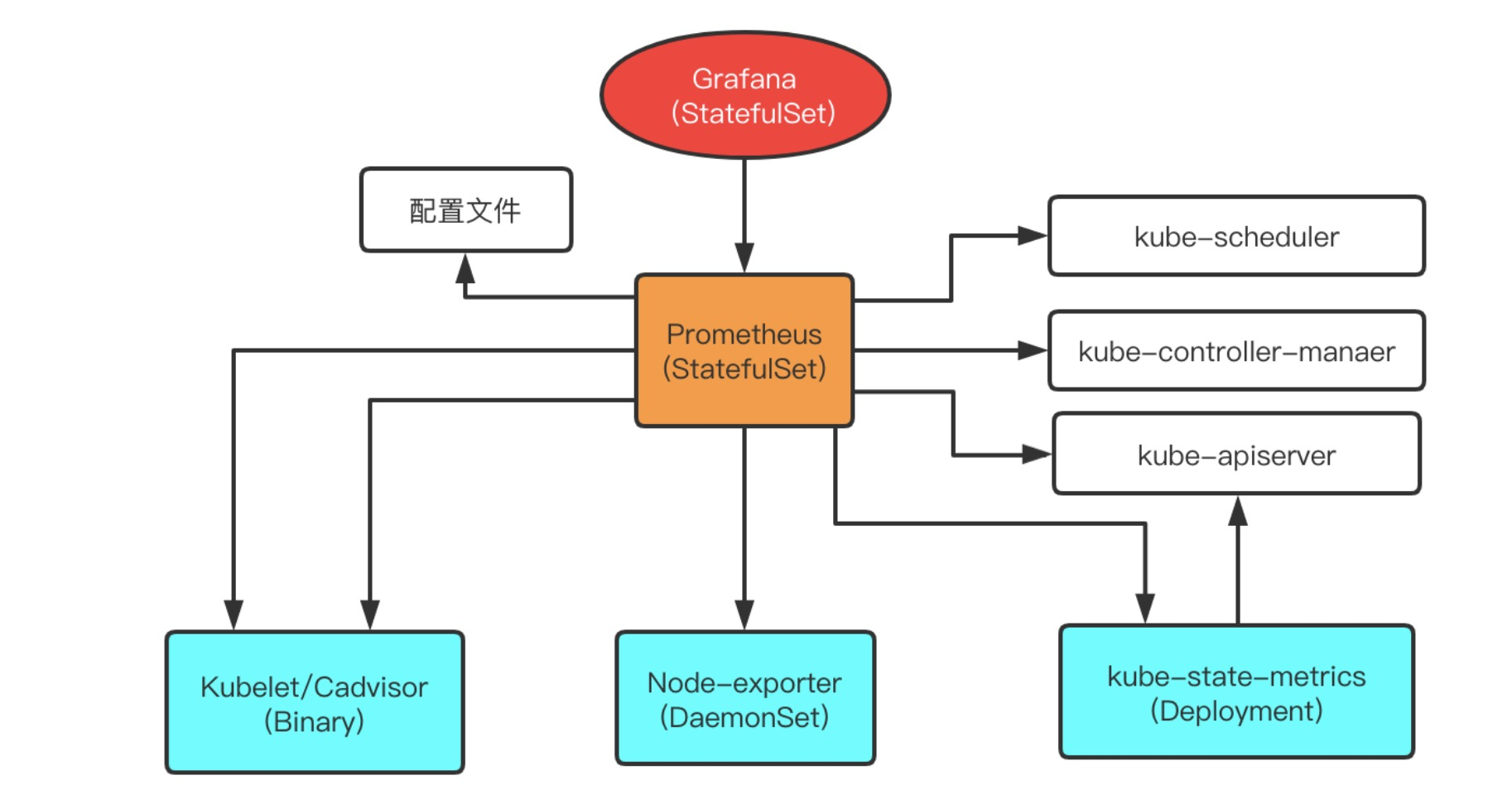
单机群部署架构
单集群架构非常简单,如图所示。使用这种方式,就可以将集群的节点,组件,资源状态,容器运行时状态都给监控起来;
3. 多集群场景的特点
如果我们现在有多个集群,并希望他们的监控数据存储到一起,可以进行聚合查询,用上述部署方案显然是不够的,因为上述方案中的Prometheus只能识别出本集群内的被监控目标,即服务发现无法跨集群。另外就是网络限制,多个集群之间的网络有可能是不通的,这就使得即使在某个集群中知道另一个集群的target地址,也没法去抓取数据。总结多集群的特点主要有:
- 服务发现隔离
- 网络隔离
那只用Prometheus能解决吗?
答案其实是能,用联邦。
Prometheus支持拉取其他Prometheus的数据到本地,称为联邦机制。这样我们就可以在每个集群内部署一个Prometheus,再在他们之上部署一个Top Prometheus,用于拉取各个集群内部的Prometheus数据进行汇总。
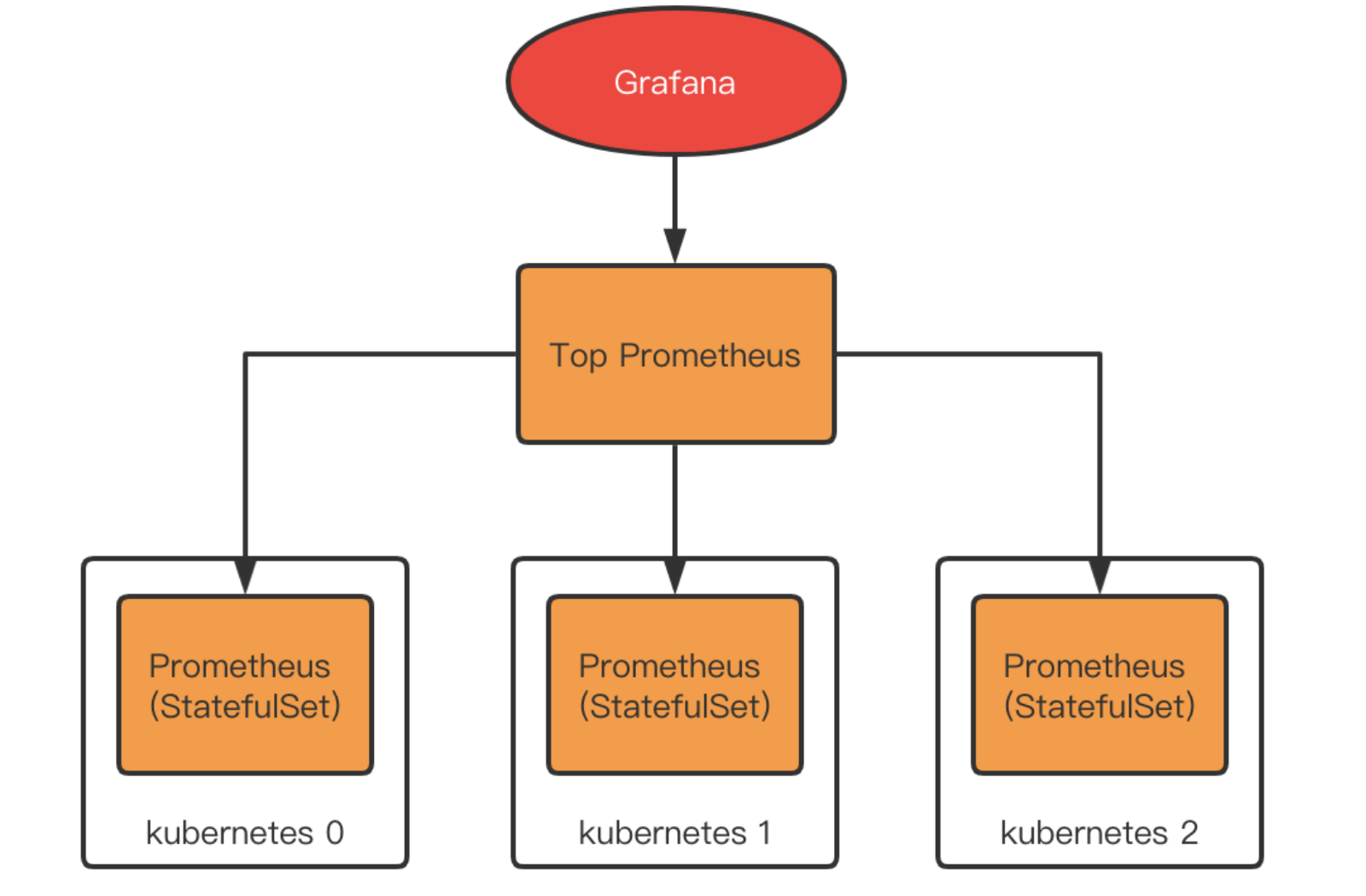
联邦的问题在哪?
联邦的方案其实也是社区所认可的,在集群规模普遍较小,整体数据量不大的情况下,联邦的方案部署简单,理解成本低,没有其他组件的引入,是一个很不错的选择。
但是联邦也有其问题。由于所有数据最终都由Top Prometheus进行存储,当总数据量较大的时候,Top Prometheus的压力将增大,甚至难抗重负,另外,每个集群中的Prometheus实际上也会保存数据(Prometheus2.x 不支持关闭本地存储),所以实际上出现了数据无意义冗余。总结而言,联邦的问题主要是。
- Top Prometheus压力大
- 数据有无意义冗余
4.用Thanos实现多集群监控
Thanos简介
Thanos 是一款开源的Prometheus 高可用解决方案,其支持从多个Prometheus中查询数据并进行汇总和去重,并支持将Prometheus本地数据传送到云上对象存储进行长期存储。官方架构图如下:
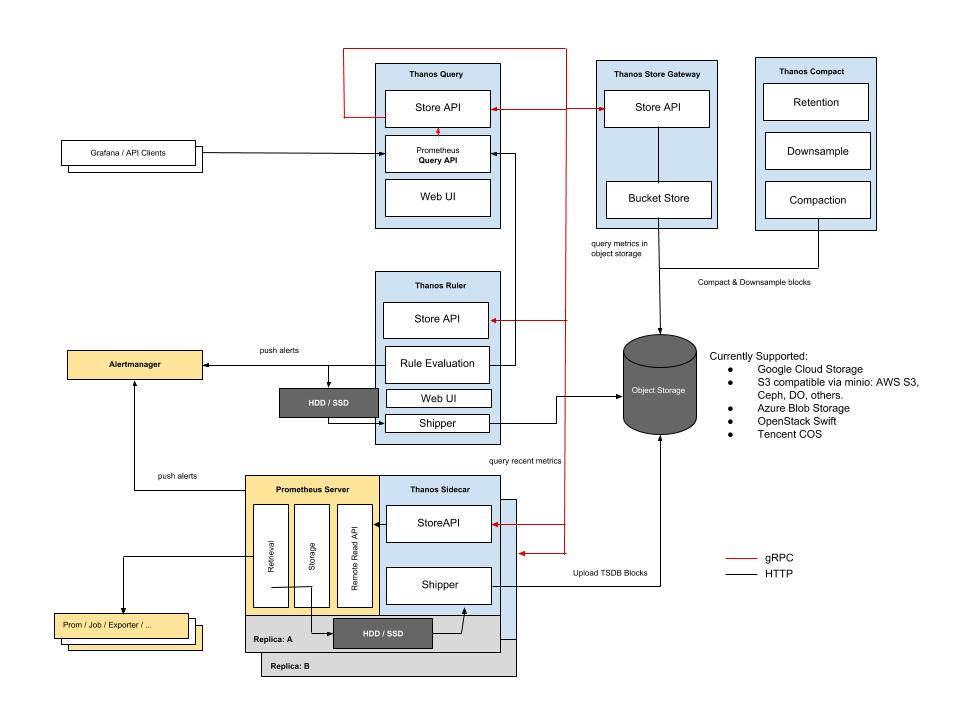
- Query: query代理Prometheus作为查询入口,他会去所有Prometheus,Store, 以及 Ruler查询数据,汇总并去重。
- Sidecar:将数据上传到对象存储,也负责接收Thanos query的查询请求。
- Ruler:进行数据的预聚合及告警。
- Store:负责从对象存储中查询数据。
简化版本图:

部署方案
使用Thanos来替代联邦方案,我们只需要将上图中的Prometheus和Thanos sidecar部署到Kubernetes集群中,将Thano query等组件部署在原来Top Prometheus的位置即可。

相比联邦的优势
使用Thanos相比于之前使用联邦,拥有一些较为明显的优势
- 由于数据不再存储在单个Prometheus中,所以整体能承载的数据规模比联邦大。
- 数据不再有不必要的冗余。
- 由于Thanos有去重能力,实际上可以每个集群中部署两个Prometheus来做数据多副本。
- 可以将数据存储到对象存储中,相比存储在本地,能支持更长久的存储。
5.总结
我们首先介绍了Prometheus的基本原理,并介绍了最为常用的使用Prometheus监控单一小集群的方案。
随后,针对多集群场景,我们还谈了联邦方式与Thanos方式各有什么优缺点。
后续我应该还会分享下三篇内容
- 1.Prometheus具体的配置说明;
- 2.Prometheus-operator部署prometheus集群;
- 3.Grafana面板展示以及PromQL语法查询;

